🔥 Платформа KCORES для больших моделей запущена! Впервые представлено подробное исследование оценки GPT-4.1 — без обмана, только干货!

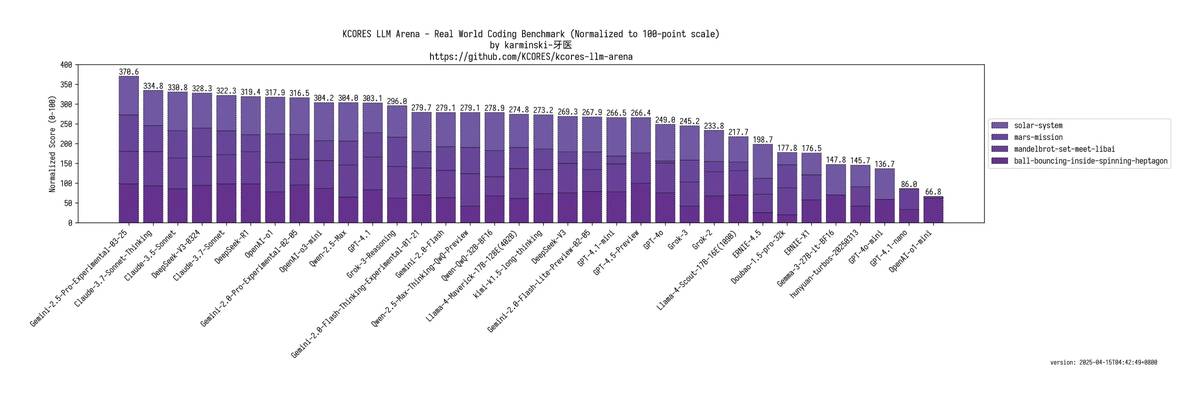
🌟 Отчет о финальной битве: 🏆 Gemini-2.5-Pro демонстрирует непревзойденный стиль, лидерство вне сомнений 💥 GPT-4.1 ≈ Qwen-2.5-Max, но OpenAI-O3-mini-high и o1 оказались сильнее 💰 GPT-4.1-mini ≈ классическая версия DeepSeek-V3, можно сказать "народная версия GPT-4.5" 😱 GPT-4.1-nano: Полностью разгромлен Wenxin Yiyan, полный крах...
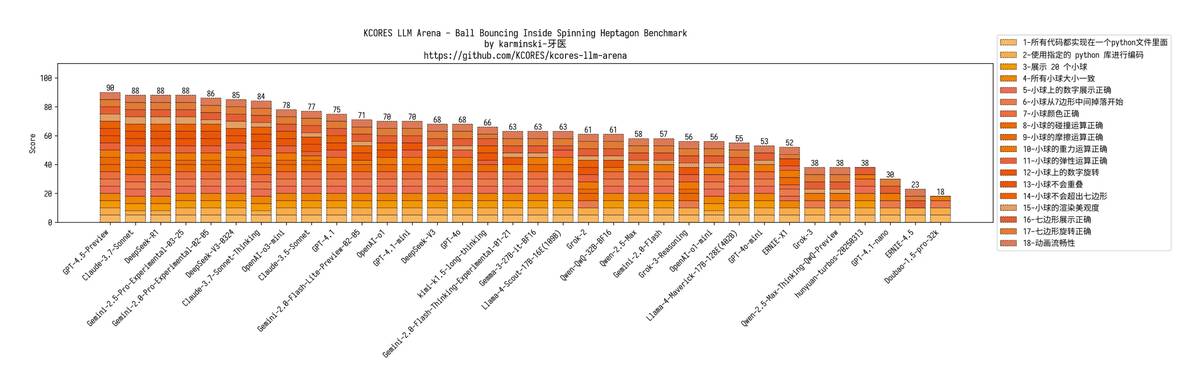
📊 Полные записи жесткого тестирования (внимание!): 1. 🎮 Вызов физического движка с 20 мячами Качество кода GPT-4.1 на высоте, но не хватает эффектов трения и вращения Версия mini также провалилась, nano-версия вообще провалилась — на поле остался один мяч
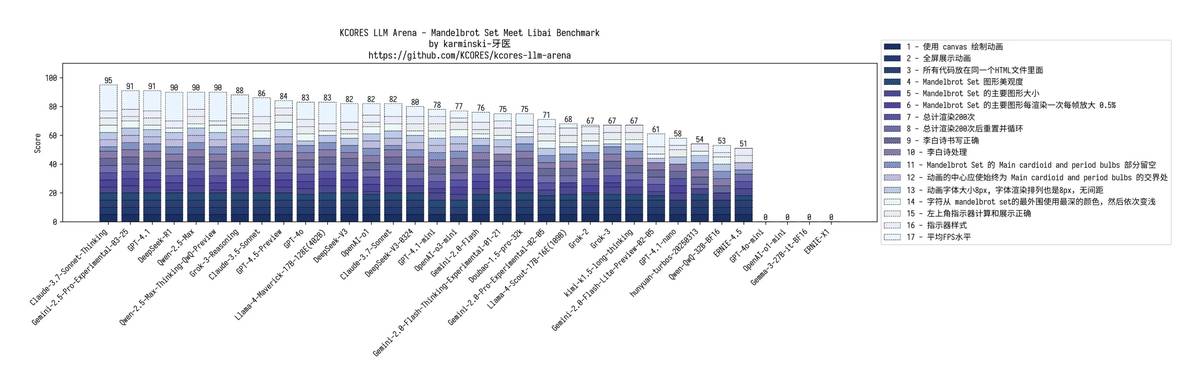
2. 🎨 Искусственное творчество Мандельброта GPT-4.1: Нарушение цветовой гаммы + переполнение изображения mini: За вычитание баллов за неполноэкранную отрисовку nano: Неудачная распознавание команд, хаотичный текст, смещение фокуса, полный коллапс
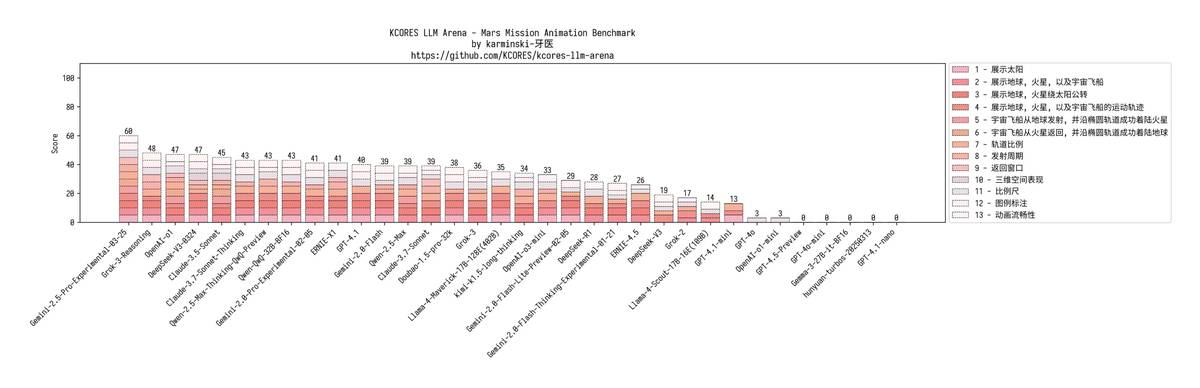
3. 🚀 Экстремальное испытание посадки на Марс Ситуация становится все более плачевной: GPT-4.1: Орбитальная путаница, все окна запуска ошибочны mini: Даже корабль не смог отрендериться nano: Прямая ошибка кода, полный отказ
4. ☄️ Большой экзамен по моделированию Солнечной системы GPT-4.1: Водород солнца перекрывает Меркурий? Возрождение гелиоцентризма? mini: Неожиданно стабильное поведение nano: Просто рисует несколько кругов для отвода глаз
💡 Финальная оценка: GPT-4.1 в этот раз сильно разочаровал, хотя и заявлялся как улучшение, оказалось "ничего особенного". За пределы совершенства? Gemini по-прежнему лучший выбор; бюджет ограничен? mini может справиться; nano... лучше вообще не использовать!
🤖 Время взаимодействия: Какой ИИ вас особенно впечатлил недавно? Кто вас удивил до чертиков? Быстрее пишите в комментарии, начинайте "конференцию по критике моделей ИИ"!
Этот обзор действительно показывает, насколько сильно модели могут различаться в конкретных задачах. Особенно удивил результат с nano-версией GPT-4.1 — не ожидал такого провала. Интересно, как эти показатели скажутся на реальной жизни использования моделей.
Этот тест показывает, как细微ые отличия в моделях могут привести к большим разрывам в производительности. Особенно удивил результат с nano-версией GPT-4.1 – я не ожидал такого провала. Интересно было бы увидеть больше подобных сравнений между другими моделями.
Эти результаты действительно удивительные! Особенно контраст между полной версией GPT-4.1 и её урезанными вариантами. Видно, как сильно оптимизация влияет на производительность моделей. Интересно, какие обновления помогут nano-версии хотя бы не падать с первой попытки.