🔥 KCORES大模型竞技场震撼上线!重磅首发【GPT-4.1极限测评】——拒绝套路,只讲干货!

🌟 巅峰对决战报:
🏆 Gemini-2.5-Pro 王者风范,霸榜实力毋庸置疑
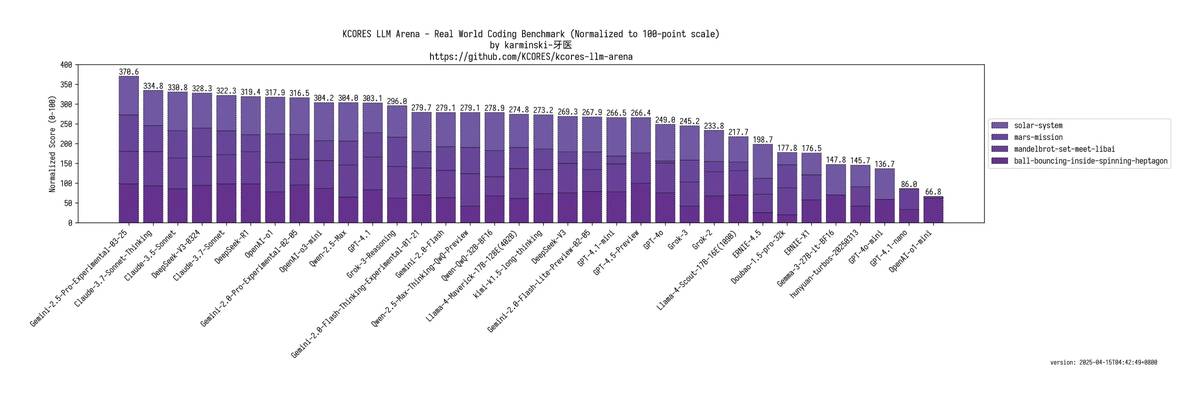
💥 GPT-4.1 ≈ Qwen-2.5-Max,竟被OpenAI-O3-mini-high和o1反超
💰 GPT-4.1-mini ≈ 经典款DeepSeek-V3,堪称”平民版GPT-4.5″
😱 GPT-4.1-nano:惨遭文心一言碾压,体验直接崩盘…
📊 硬核测试全记录(高能预警):
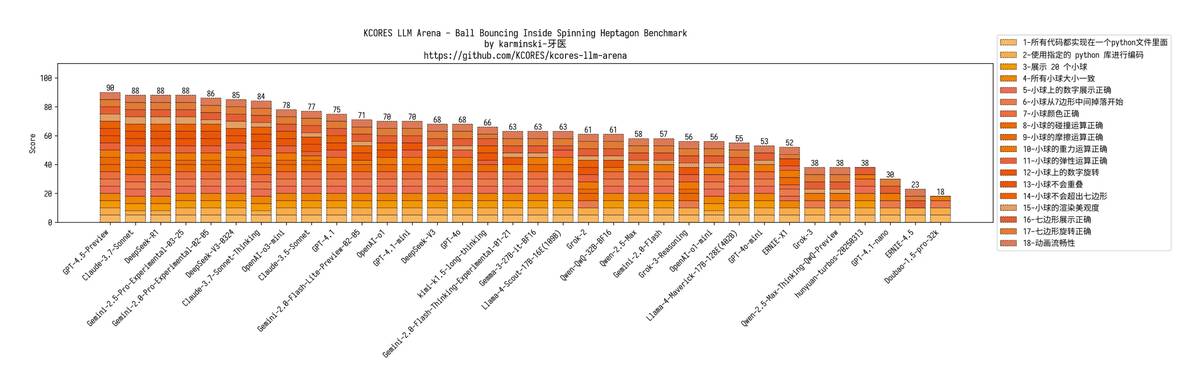
1. 🎮 20球物理引擎挑战
GPT-4.1代码质量在线,可惜少了摩擦旋转特效
mini版同样翻车,nano版更惨——全场只剩1颗球孤独蹦跶
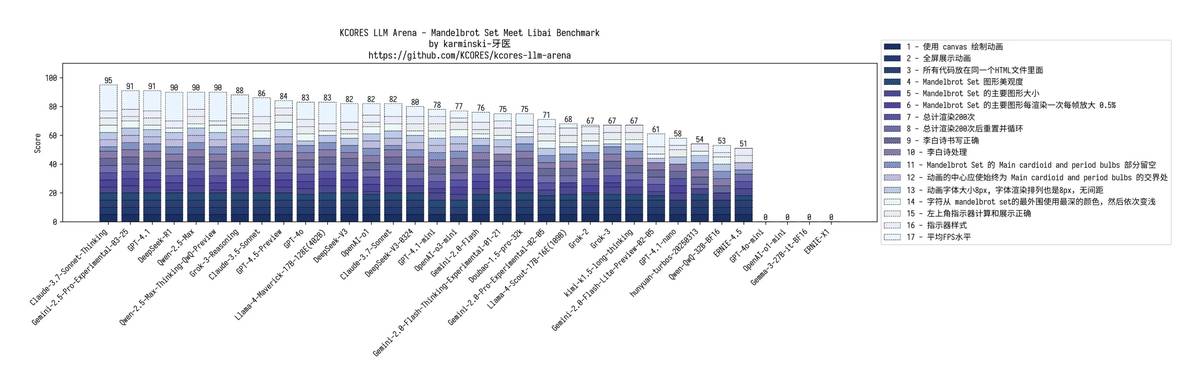
2. 🎨 曼德博集合艺术创作
GPT-4.1:色系全反+画面溢出
mini:因未全屏渲染扣分
nano:指令识别失败,文本乱入,核心错位,全面崩盘
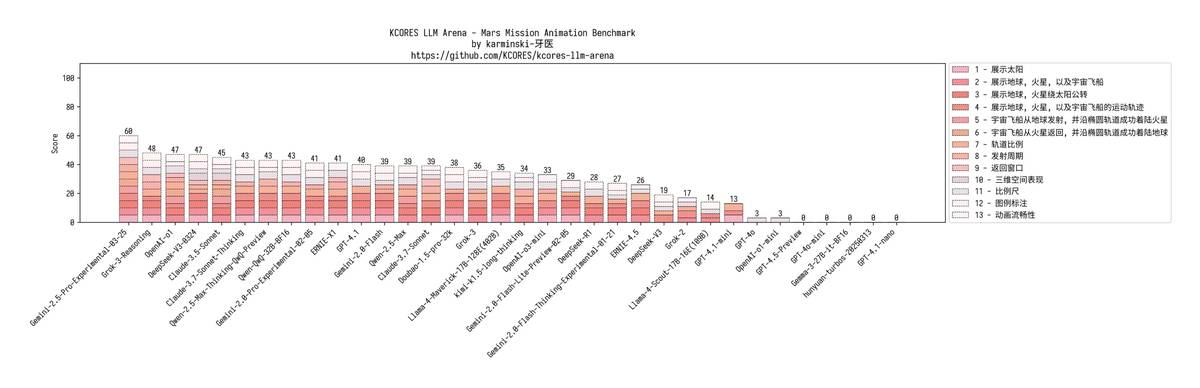
3. 🚀 火星登陆极限测试
战况逐渐惨烈:
GPT-4.1:轨道错乱,发射窗口全错
mini:连星球飞船都没渲染出来
nano:代码直接报错,彻底罢工
4. ☄️ 太阳系模拟大考
GPT-4.1:水星太阳重叠?地心说文艺复兴?
mini:意外表现稳健
nano:随便画几个圈敷衍了事
💡 终极锐评:
GPT-4.1这次真是期待越高失望越大,号称升级实则”平平无奇”。
追求极致?Gemini仍是首选;预算有限?mini勉强能战;至于nano…建议直接放弃治疗!
🤖 互动时间:
最近哪款AI让你眼前一亮?又被谁雷到外焦里嫩?
速来评论区,开启”AI模型吐槽大会”!
Wow, the performance gaps between these models are way bigger than I expected! Especially that nano version of GPT-4.1 really struggled in all those tests – didn’t even render a proper spaceship for the Mars landing challenge. It’s fascinating to see how even small changes in model size can lead to such dramatic differences in capabilities. I wonder what this means for future AI development priorities.
Absolutely, it’s amazing how sensitive these models are to scaling. The nano version’s struggles highlight the importance of finding the right balance between efficiency and capability. I think this will push developers to explore more innovative ways to optimize smaller models without sacrificing performance. Thanks for your insightful comment—really got me thinking!
Wow, the results are really surprising! Especially how GPT-4.1 performed so well overall but had some major hiccups in those specific challenges. It’s interesting to see how different models handle complex tasks when pushed to their limits. I wonder if these tests will change anything for future updates or releases.
Absolutely, it’s fascinating to see how each model reacts under pressure. While these tests might not directly influence future updates, they do provide valuable insights for developers. It’s likely we’ll continue seeing improvements as teams learn from these findings. Thanks for your thoughtful comment—it’s clear you’re deeply engaged with the topic!
Wow, the performance gaps between these models are way more dramatic than I expected. Especially surprising was how GPT-4.1’s nano version completely fell apart in those tests—it’s a good reminder that smaller versions aren’t just scaled-down versions of the full model. I wonder how much of this comes down to resource limitations versus fundamental design differences. The Mars landing test failure for nano was especially funny (in a sad way).
Wow, the nano version of GPT-4.1 really didn’t do well at all in those tests. It’s surprising to see how much of a difference there is between the different versions. I wonder if the higher-end models will hold up better against more complex tasks. This evaluation definitely gives a good sense of where each model stands.
Absolutely, the performance gap between versions can be quite striking. I think the higher-end models are likely to handle complex tasks more effectively, but it’s always good to see direct comparisons like this. Your curiosity reflects what many of us are thinking—thanks for sharing! I personally find these evaluations fascinating because they highlight how nuanced the differences can be.
Wow, the nano version of GPT-4.1 really didn’t hold up well in those tests. It’s interesting to see how different models handle complex tasks like the Mars landing simulation—some really faltered under pressure. I wonder if these results will change how people think about model size and capability. The physical engine challenge was especially telling for comparing performance across versions.
Wow, the performance gaps between these models are way more dramatic than I expected. Especially shocking to see GPT-4.1-nano completely fall apart in those tests. It looks like even the top-tier models can struggle with really complex tasks when pushed to their limits. But I’m curious – did they mention anything about how long it took each model to generate responses?
Wow, the results are really surprising! Especially how GPT-4.1 performed so well overall but had some major hiccups in specific tests like the physics engine. It’s interesting to see how different models handle niche tasks like Mandelbrot art compared to more general challenges like Mars landing simulations.