Récemment, OpenAI a lancé trois nouveaux modèles : GPT-4.1, GPT-4.1 mini et GPT-4.1 nano. Ces modèles surpassent de manière globale GPT-4o et GPT-4o mini (Figure 2️⃣). Ils sont même meilleurs que GPT-4.5 (un peu abstrait—4.1 > 4.5 🤣). (Seulement disponibles via API.)
La famille GPT-4.1 présente des améliorations significatives en codage et en suivi des instructions. Tous les modèles disposent d'une longueur de contexte de 1 million de tokens (Figure 3️⃣, de Cyber Zen Heart).
Comparaison centrale de la famille GPT-4.1 ⬇️ 1️⃣ Positionnement et configurations des modèles · GPT-4.1 : Le modèle idéal pour les tâches complexes Sortie maximale : 32k tokens Modalité : Texte, entrée image + sortie texte · GPT-4.1 mini Positionnement : Équilibre entre vitesse et coût Même configuration que GPT-4.1 mais à un prix inférieur · GPT-4.1 nano Positionnement : Faible latence, haute efficacité coût Même famille de configuration, 50 % de latence plus rapide que 4o

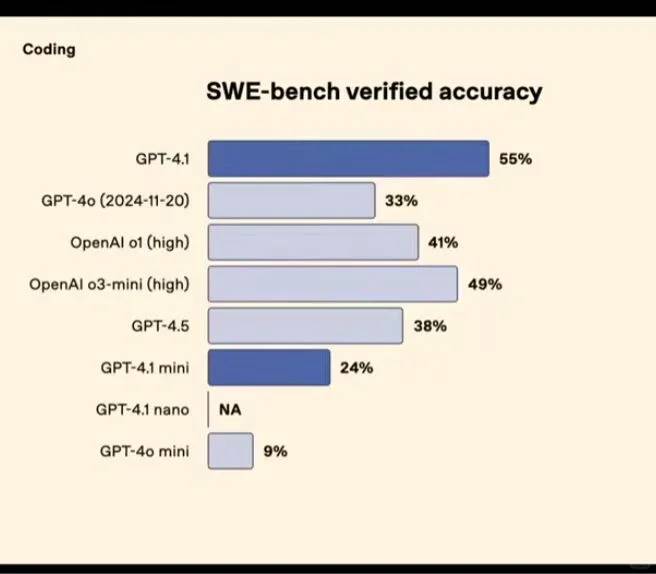
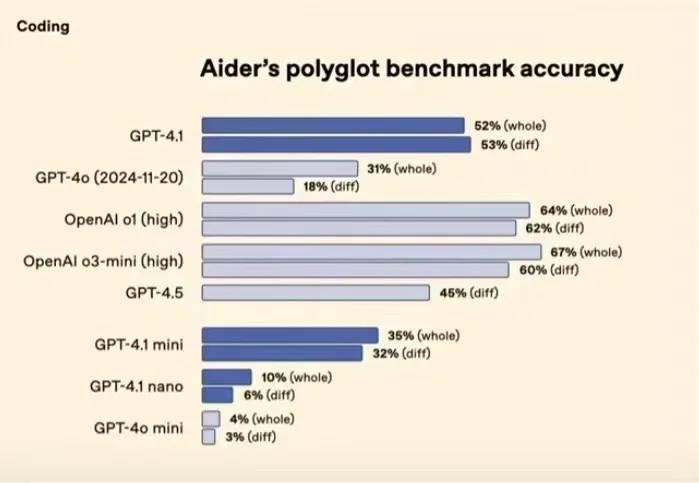
2️⃣ Performance ◦ Tâches de codage (benchmark Aider, Figure 4️⃣) ▪ 4.1 (52 %), 4.1 mini (35 %), 4.1 nano (10 %) ◦ SWE-bench (Figure 5️⃣) ▪ 4.1 (55 %), mini (24 %) ◦ Tâches vidéo (Video-MME) ▪ 4.1 (72 %) surpasse nettement 4o (65 %)
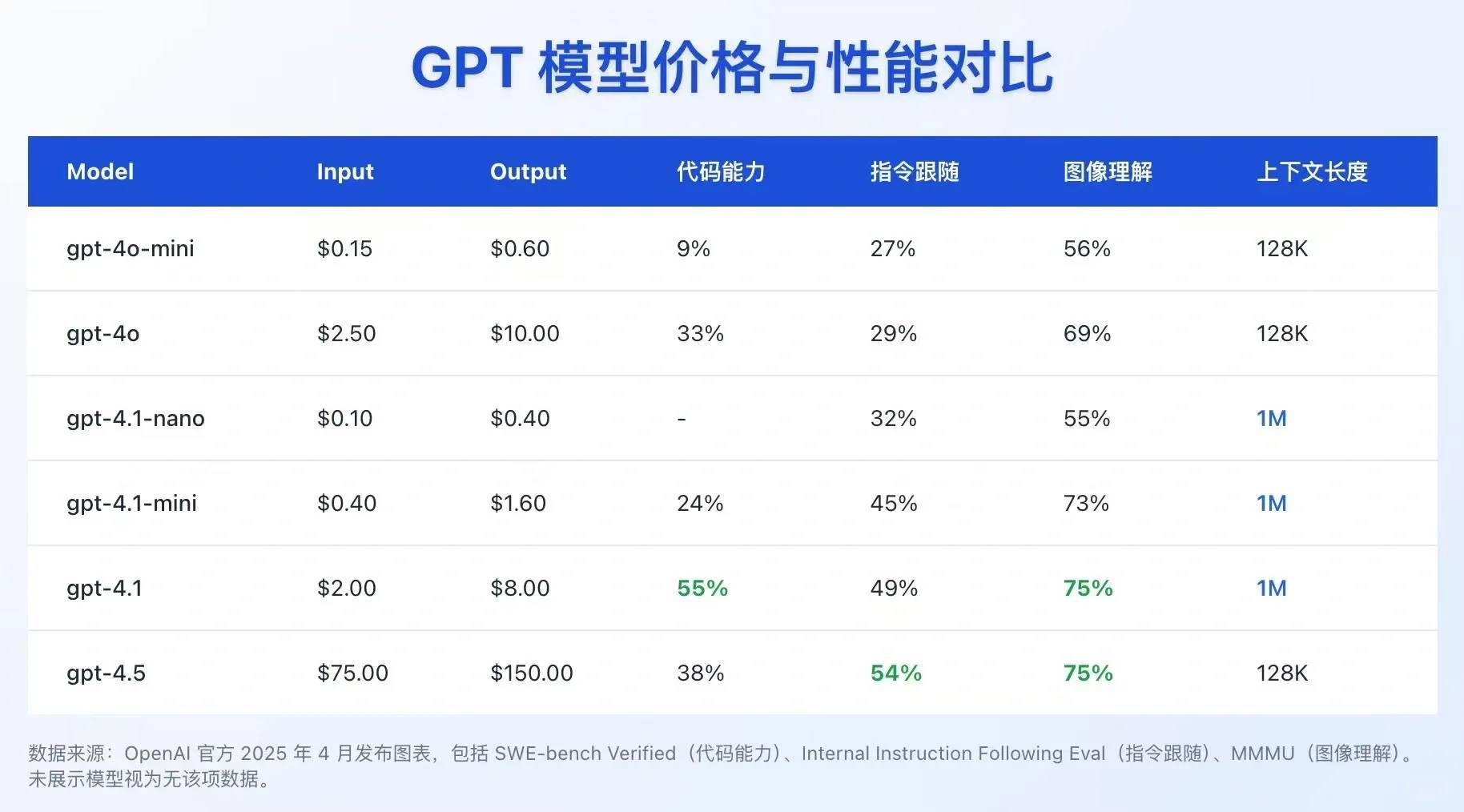
3️⃣ Prix et coût ◦ Coût d'entrée (par million de tokens) ▪ 4.1 ($2,00), mini ($0,40), nano ($0,10) ◦ Coût de sortie (par million de tokens) ▪ 4.1 ($8,00), mini ($1,60), nano ($0,40)
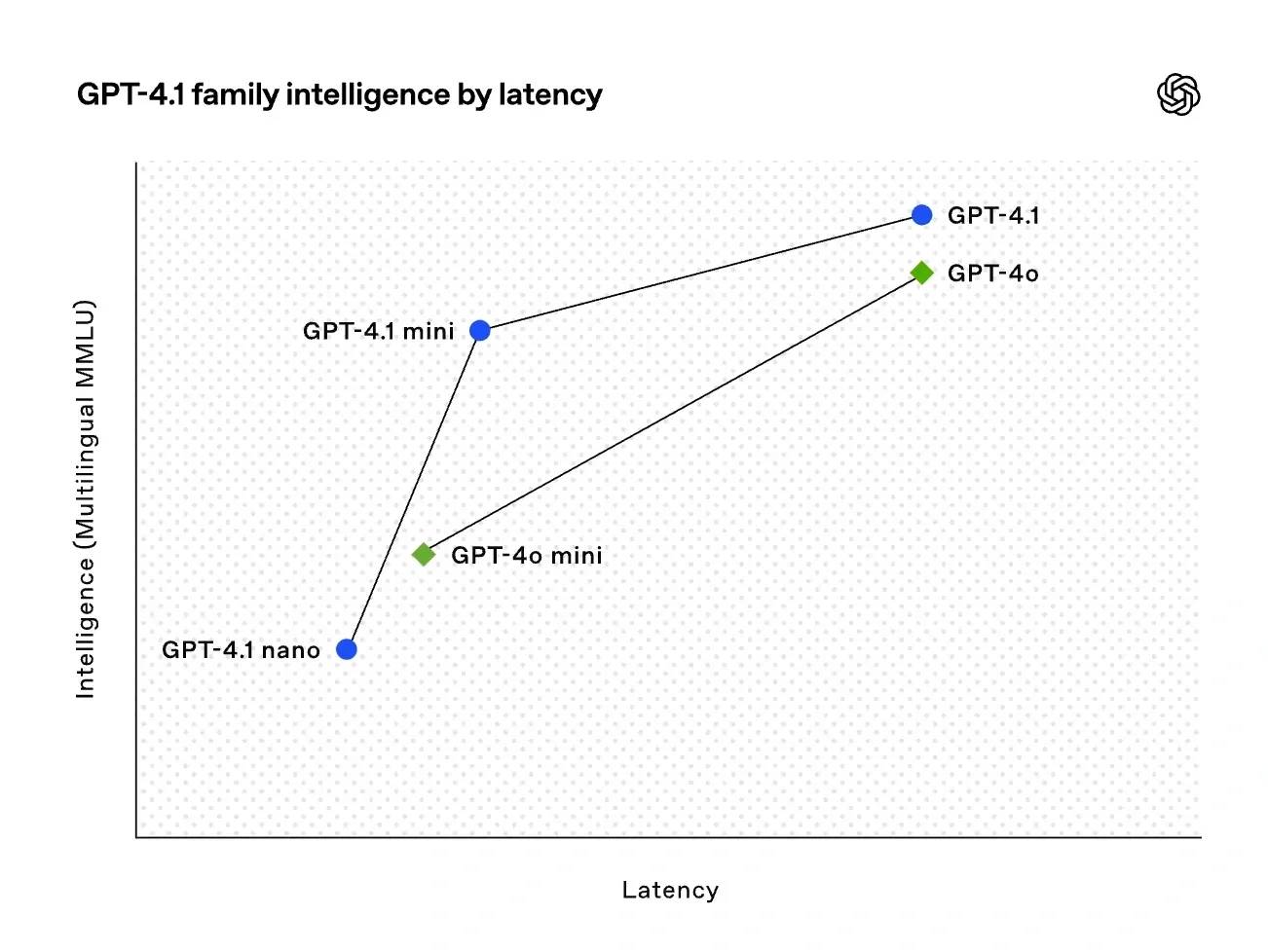
Série GPT-4.1 offrant différents niveaux (standard, mini, nano) pour répondre aux besoins allant des tâches complexes aux scénarios temps réel à faible coût. Cas d'utilisation recommandés ⬇️ ◦ Besoins de haute performance : G4.1 ou o3-mini-high (67 % de précision) ◦ Temps réel, faible latence : 4.1 nano (le plus rapide et le moins cher) Nano est actuellement le modèle le plus rapide et le plus abordable.
Suivez-moi pour plus de mises à jour de haute qualité— Je vous apporterai régulièrement les dernières tendances et insights du secteur de l'IA 😎 @TechPotato
Comments are closed.