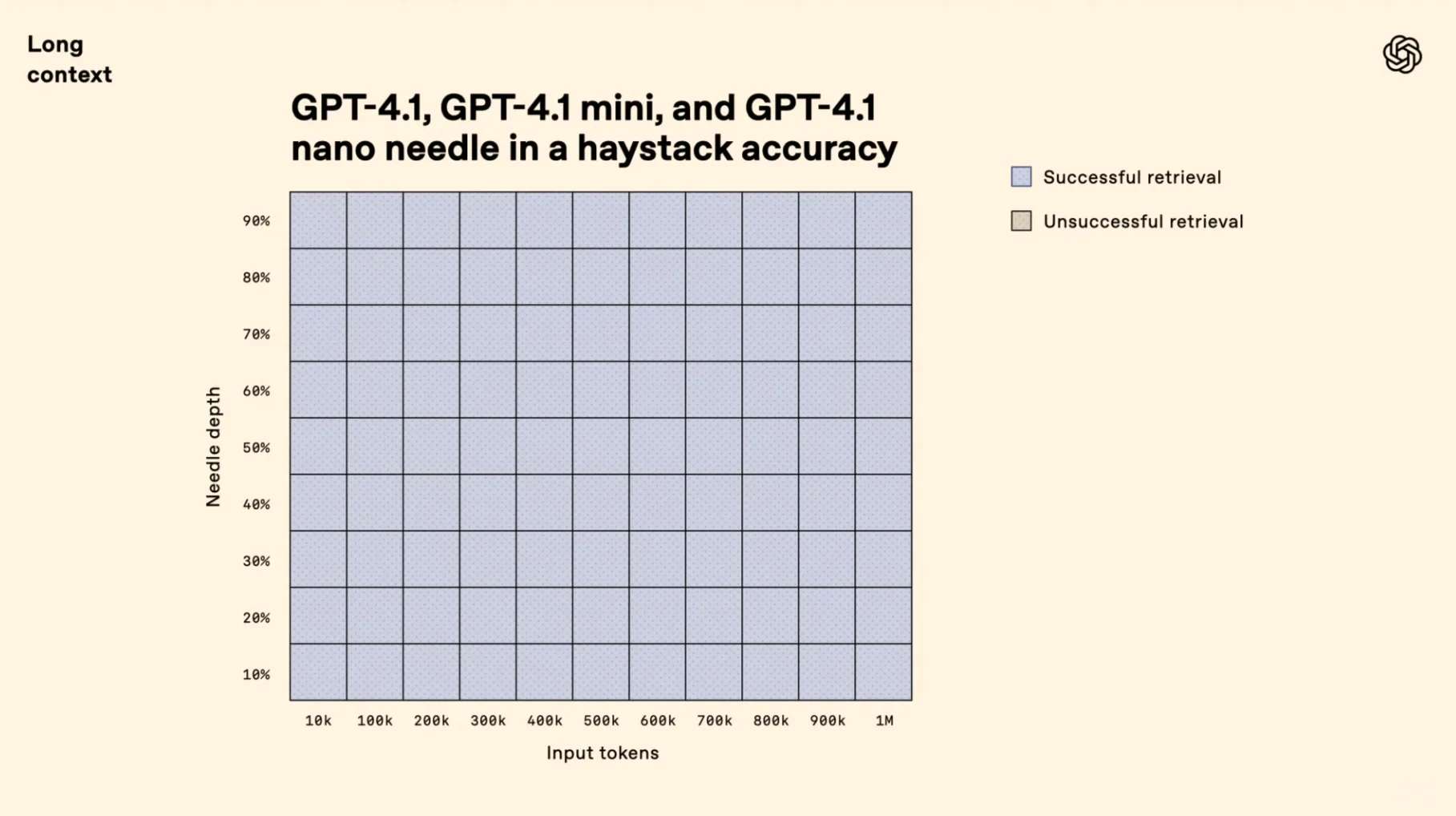
Introducing the game-changing trio: GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano—outshining their predecessors with remarkable enhancements in coding prowess and instruction execution. These powerhouse models boast an expansive 1-million-token context window, delivering unprecedented long-context mastery. Witness how GPT-4.1 dominates industry benchmarks with its cutting-edge capabilities:
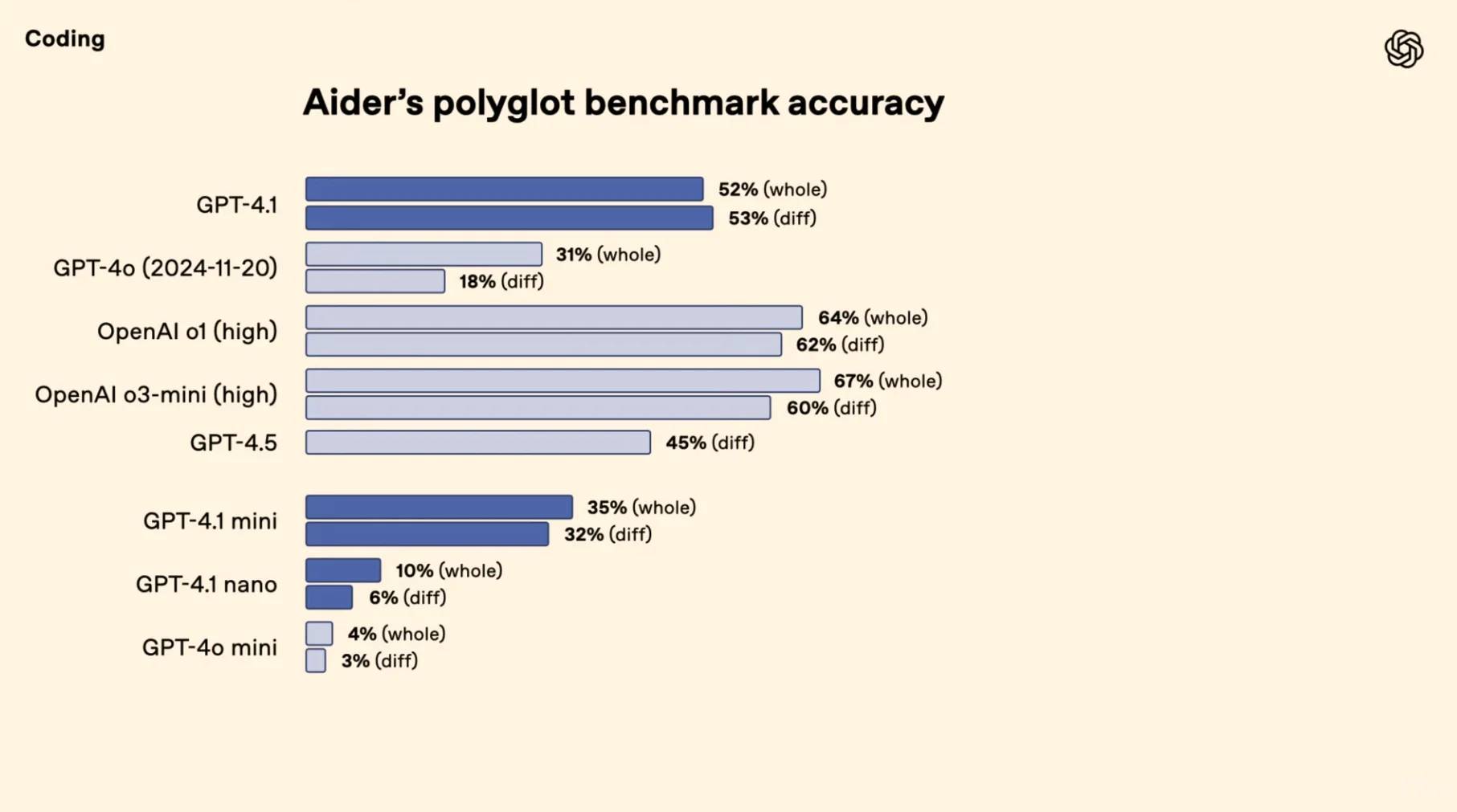
[🚀] **Coding Mastery**: Crushing the competition, GPT-4.1 achieves a staggering 54.6% pass rate on SWE-bench—soaring 21.4% above GPT-4o and 26.6% beyond GPT-4.5 to claim the coding crown.
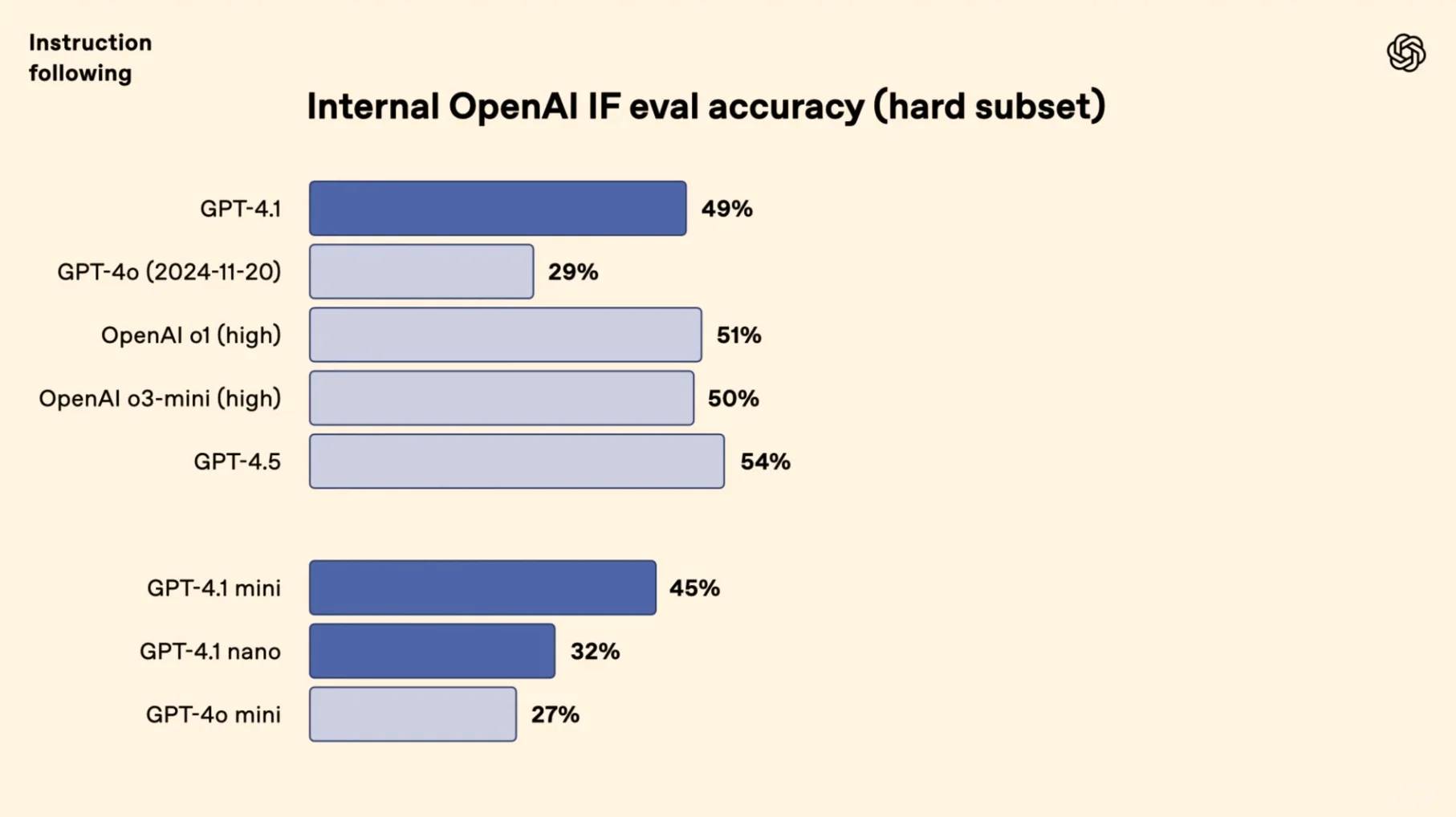
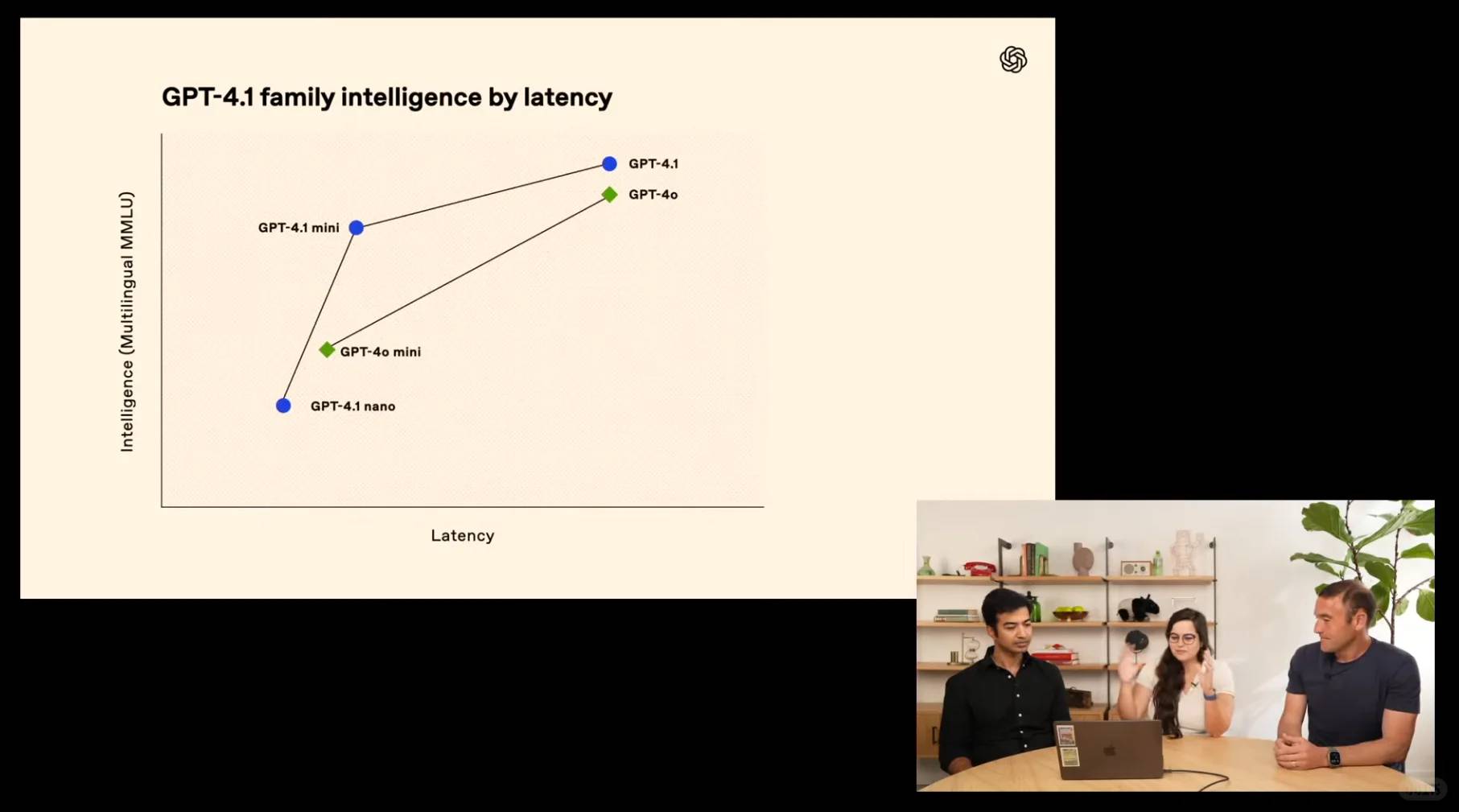
[🎯] **Precision Execution**: On Scale’s MultiChallenge, GPT-4.1 hits 38.3%, demonstrating a 10.5% leap in instruction-following finesse over GPT-4o.
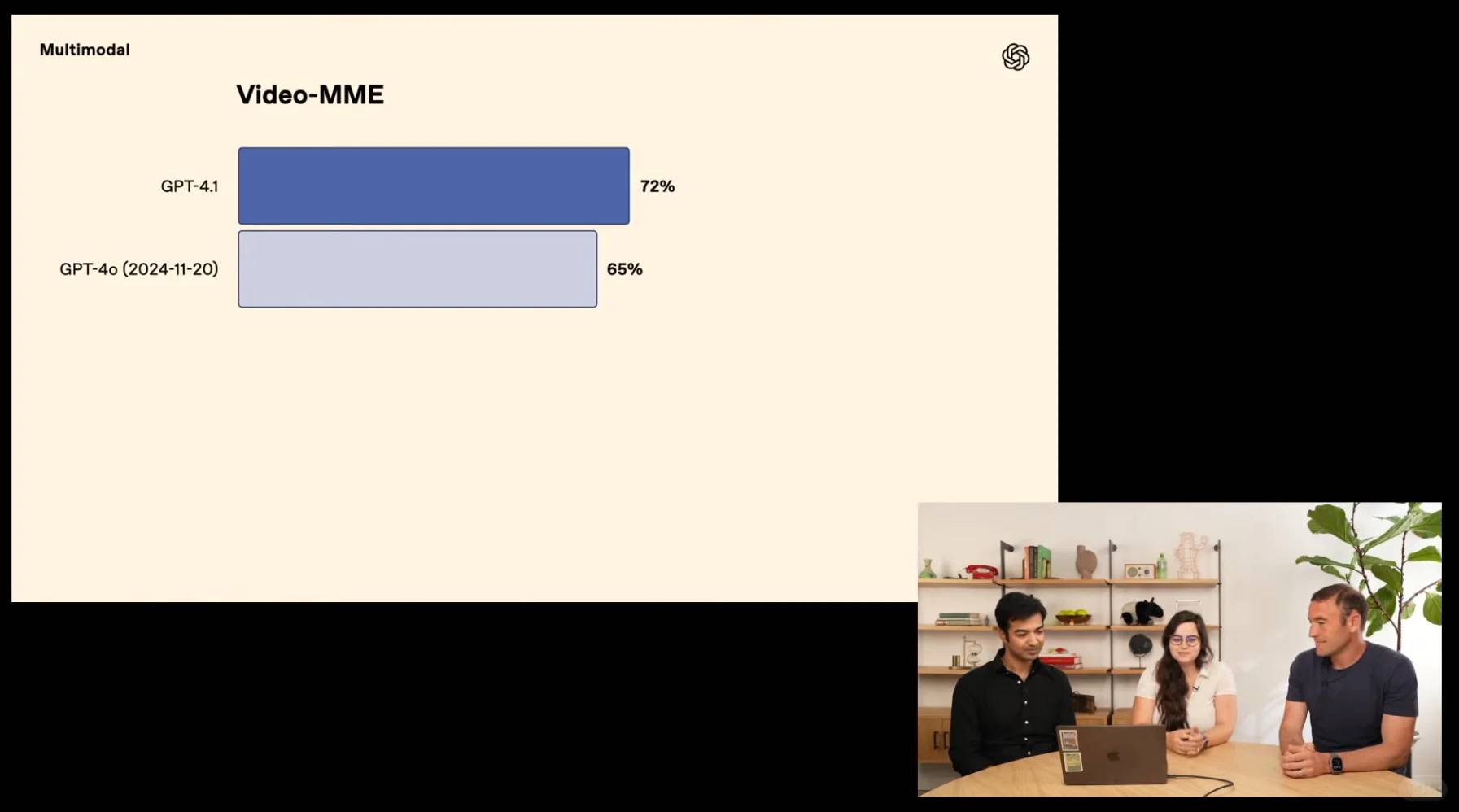
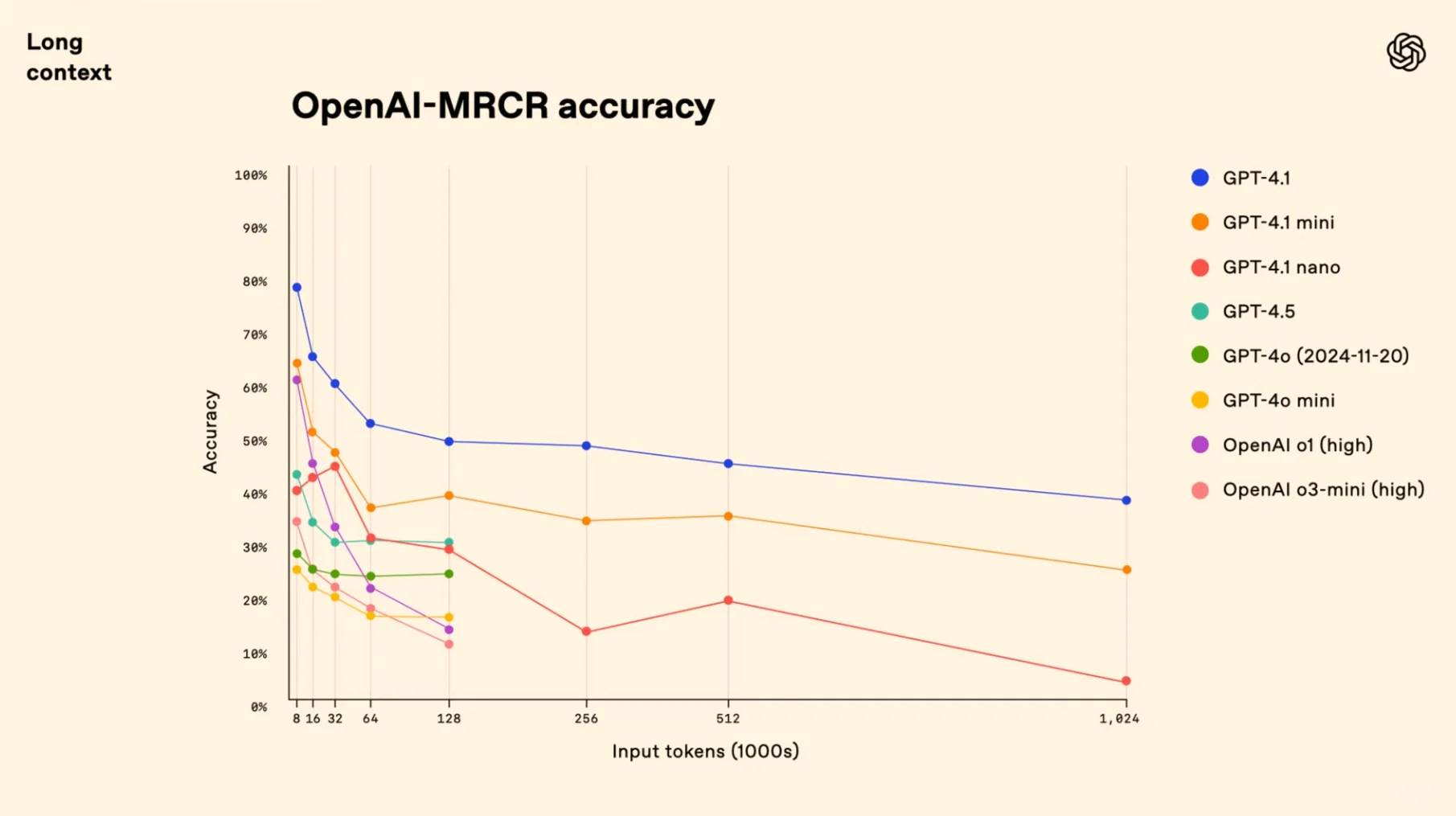
[🔍] **Context Champion**: Redefining boundaries, GPT-4.1 scores a record-breaking 72.0% on Video-MME’s multimodal assessment, eclipsing GPT-4o by an impressive 6.7% margin.

Wow, that 54.6% pass rate on SWE-bench is insane! I can’t believe how much better GPT-4.1 is at coding compared to the previous versions. The 1-million-token context window also sounds like it would be a game-changer for complex tasks. OpenAI is really pushing the boundaries with these updates.
Absolutely agree! The improvements in both coding capabilities and context handling are truly impressive. It’s exciting to see how these advancements can unlock new possibilities for developers and creatives alike. Thanks for your insightful comment—keep sharing your thoughts!
Wow, that 54.6% pass rate on SWE-bench is insane! I can’t believe how much better it is compared to previous versions. The long-context stuff sounds like a game-changer for complex projects. OpenAI really outdid themselves this time.
Absolutely agree! The improvements are truly remarkable, and that pass rate is impressive. It’s exciting to see how these advancements will empower developers tackling large-scale projects. Thanks for your insightful comment—keep sharing your thoughts!
Wow, that 54.6% pass rate on SWE-bench is insane! It’s crazy to see how much more GPT-4.1 can handle compared to its predecessors. I’m really curious to test it out for some complex coding projects. This could seriously change the game for developers.
Absolutely, the improvements in GPT-4.1 are remarkable! The higher pass rate on benchmarks like SWE-bench shows just how powerful this model has become for complex tasks. I think you’ll find it incredibly helpful for challenging coding projects. Exciting times ahead for developers! Thanks for sharing your thoughts!
Wow, that 54.6% pass rate on SWE-bench is insane! I can’t believe how much better it is compared to the previous versions. The ability to handle such a huge context window must give it an edge in complex tasks. OpenAI really outdid themselves this time.